D Vector Speaker Recognition. The x-vector concept is newer and the name of the method is similar to i-vector to suggests that this representation can be used instead of i-vectors in state-of-the-art speaker or language recognition systems. X-vector Feature Extraction Model. Duced by the self-attentive speaker embeddings is consistent with both short and long testing utterances. Vector Quantization Approach for Speaker Recognition using MFCC and Inverted MFCC Satyanand Singh Associate Professor Dept of Electronics and Comm Engineering St Peters Engineering College Near Forest Academy Dhoolapally Hyderabad Dr.
Github Liusongxiang Speaker Verification D Vector Implementation Of State Of The Art D Vector Approach For Speaker Verification
Github Liusongxiang Speaker Verification D Vector Implementation Of State Of The Art D Vector Approach For Speaker Verification From github.com
More related: Coeur D Alene Honda Powersports - Ferrari California T Price 2020 - G Reg Mini Cooper - Change Start Time Youtube Video -
Burton and John E. We use a combination of Linear Discriminant Anal-ysis LDA and Within Class Covariance Normalization. While i-vectors were originally proposed for speaker verification they have been applied to many problems like language recognition speaker diarization emotion recognition age estimation and anti-spoofing. Rajan Professional Member ACM. I-vectors are extracted in a way that makes no distinction between channel and speaker variability. On the other hand d-vector is extracted using DNN.
Korean manual is included 2019_LG_SpeakerRecognition_tutorialpdf.
Duced by the self-attentive speaker embeddings is consistent with both short and long testing utterances. Its free to sign up and bid on jobs. Search for jobs related to D vector speaker recognition or hire on the worlds largest freelancing marketplace with 20m jobs. Given a set of enrolled speaker vectors and a single test speaker vector usually the mean of. ResNet-based feature extractor global average pooling and softmax layer with cross-entropy loss. This paper presents a novel approach on text-dependent biometric speaker verification SV based on the ensemble of two feature extraction and classification processes using Hidden Markov Models in a Universal Background Model framework HMM-UBM and d-Vectors derived from a Deep Learning Network DNN structure.
 Deep Learning In Speaker Recognition Springerlink
Source: link.springer.com
Deep Learning In Speaker Recognition Springerlink
Source: link.springer.com
Rolled speaker had 5 unique utterances and each utterance had a variable number of 400-length d-vectors.
 Speaker Verification Using I Vectors Matlab Simulink
Source: mathworks.com
Speaker Verification Using I Vectors Matlab Simulink
Source: mathworks.com
Speech is the most natural way of communicating.
 Source: 4k8k.xyz
Source: 4k8k.xyz
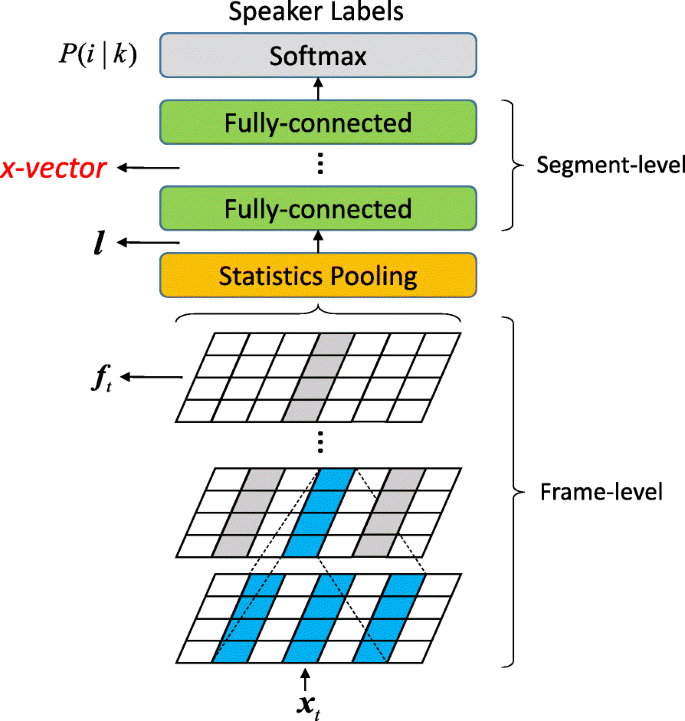
Robust DNN embeddings for speaker recognition by David Snyder Daniel Garcia-Romero Gregory S.
2
Source:
Search for jobs related to D vector speaker recognition or hire on the worlds largest freelancing marketplace with 20m jobs.
 Introducing Phonetic Information To Speaker Embedding For Speaker Verification Eurasip Journal On Audio Speech And Music Processing Full Text
Source: asmp-eurasipjournals.springeropen.com
Introducing Phonetic Information To Speaker Embedding For Speaker Verification Eurasip Journal On Audio Speech And Music Processing Full Text
Source: asmp-eurasipjournals.springeropen.com
Unlike other forms of identification such as passwords or keys speech is the most non-intrusive as a biometric.
 Asvtorch Toolkit Speaker Verification With Deep Neural Networks Sciencedirect
Source: sciencedirect.com
Asvtorch Toolkit Speaker Verification With Deep Neural Networks Sciencedirect
Source: sciencedirect.com
This paper presents a novel approach on text-dependent biometric speaker verification SV based on the ensemble of two feature extraction and classification processes using Hidden Markov Models in a Universal Background Model framework HMM-UBM and d-Vectors derived from a Deep Learning Network DNN structure.
 Speaker Diarization Separation Of Multiple Speakers In An By Jaspreet Singh Datadriveninvestor
Source: medium.datadriveninvestor.com
Speaker Diarization Separation Of Multiple Speakers In An By Jaspreet Singh Datadriveninvestor
Source: medium.datadriveninvestor.com
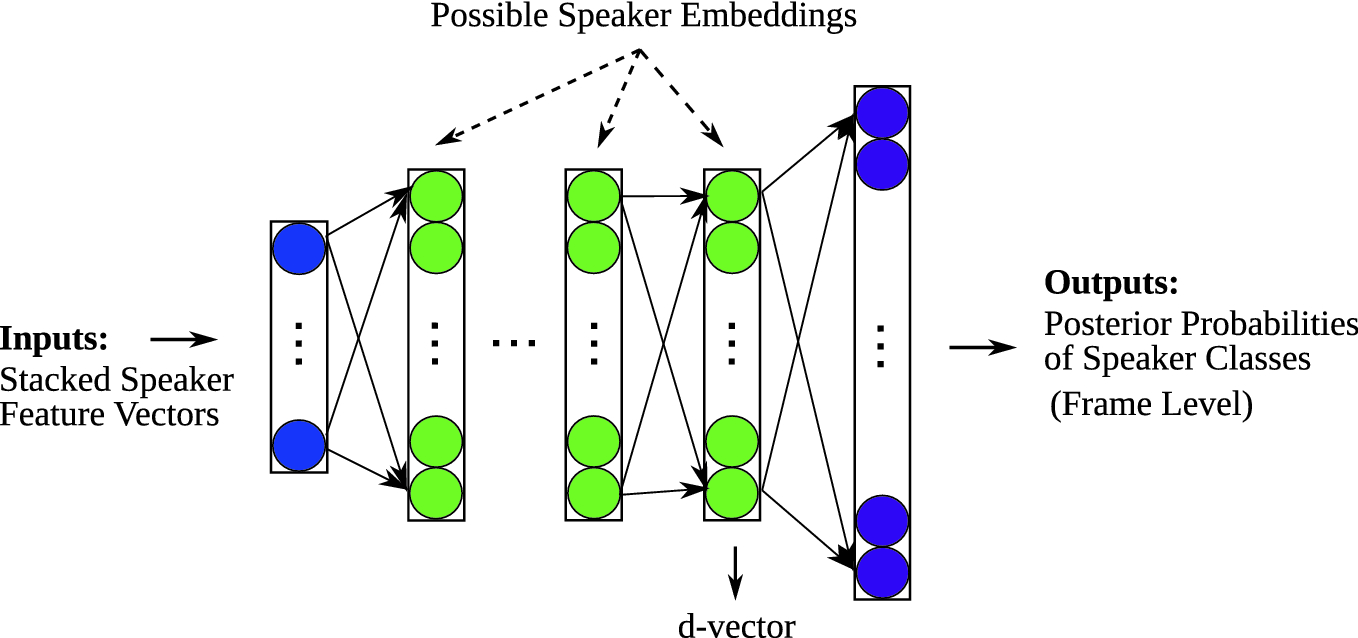
To extract a d-vector a DNN model that takes stacked filterbank features similar to the DNN acoustic model used in ASR and generates the one-hot speaker label or the speaker probability on the output is trained.
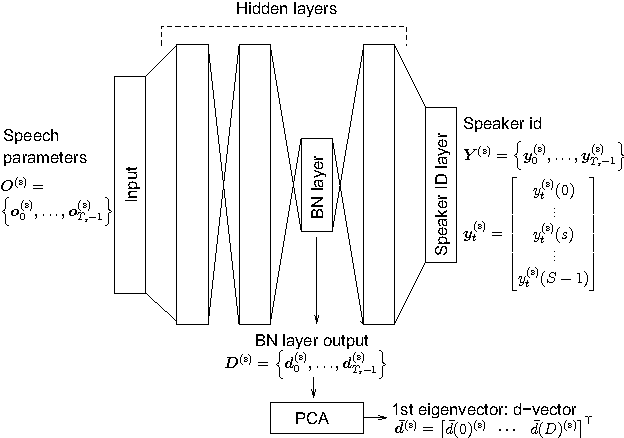
 Speaker Adaptation In Dnn Based Speech Synthesis Using D Vectors Semantic Scholar
Source: semanticscholar.org
Speaker Adaptation In Dnn Based Speech Synthesis Using D Vectors Semantic Scholar
Source: semanticscholar.org
ResNet-based feature extractor global average pooling and softmax layer with cross-entropy loss.
 Pdf Improved Deep Speaker Feature Learning For Text Dependent Speaker Recognition Semantic Scholar
Source: semanticscholar.org
Pdf Improved Deep Speaker Feature Learning For Text Dependent Speaker Recognition Semantic Scholar
Source: semanticscholar.org
The dialect recognition is done with x-vector speaker embedding which is trained for speaker recognition using Voxceleb1 and Voxceleb2 datasets.
2
Source:
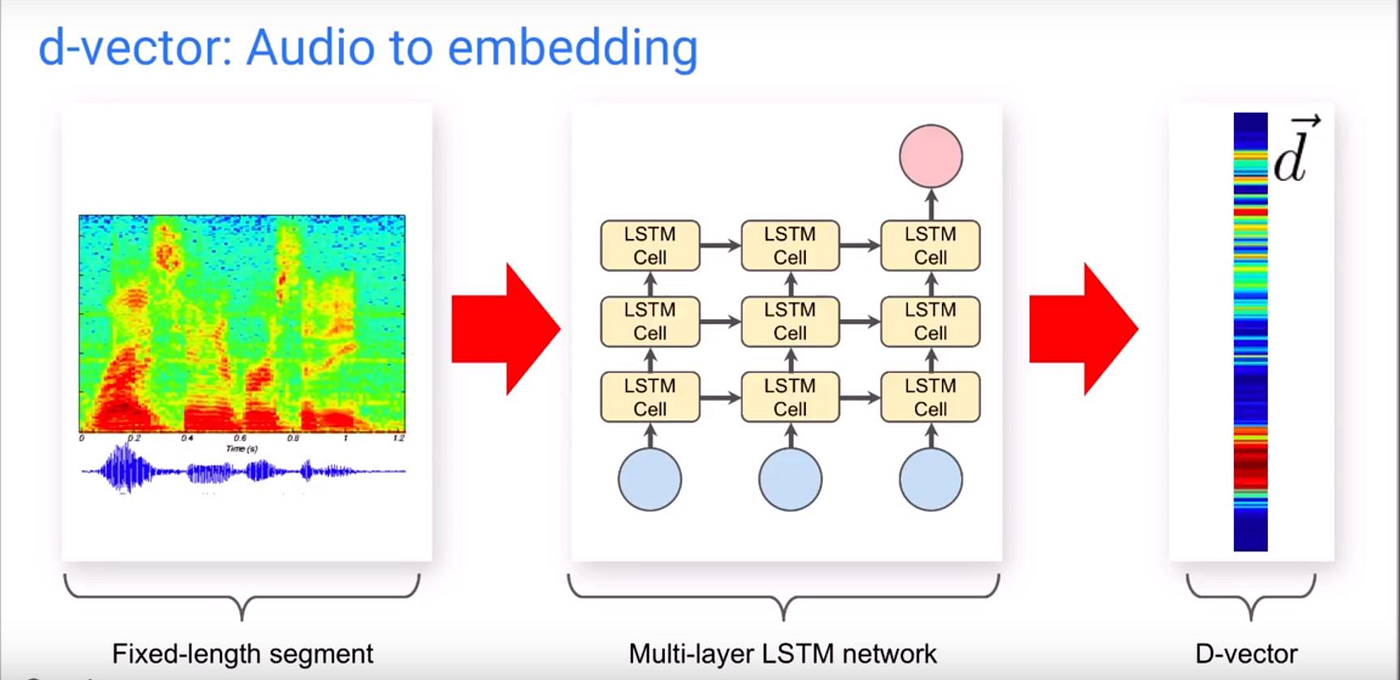
In this paper we build on the success of d-vector based speaker verification systems to develop a new d-vector based approach to speaker diarization.
2
Source:
Index Terms speaker recognition deep neural networks data augmentation x-vectors 1.
 Speaker Adaptation In Dnn Based Speech Synthesis Using D Vectors Semantic Scholar
Source: semanticscholar.org
Speaker Adaptation In Dnn Based Speech Synthesis Using D Vectors Semantic Scholar
Source: semanticscholar.org
This type of extraction results in a d-vector.
O6tarhdztyrcpm
Source:
The explored factors that appeared valuable are listed be-low.
2
Source:
Automatic speaker recognition ASR is a challenging task when the duration of the test speech is very short ie a few seconds.
2
Source:
This type of extraction results in a d-vector.
2
Source:
So the problem of channel variability has to be dealt with in construct-ing classifiers for speaker recognition using i-vectors as features.
2
Source:
Given a set of enrolled speaker vectors and a single test speaker vector usually the mean of.
Github Liusongxiang Speaker Verification D Vector Implementation Of State Of The Art D Vector Approach For Speaker Verification
Source: github.com
In this paper we build on the success of d-vector based speaker verification systems to develop a new d-vector based approach to speaker diarization.
